|
Введение
Одной из основных задач информатики является привязка фрагмента информации к
тому конкретному месту в более широком информационном поле, где он локализован
(фрагмента географической карты - к своему месту на общем плане местности,
стихотворной строки - к своему месту в тексте и т.д.). Необходимо подчеркнуть,
что в реальных задачах такого рода привязываемый к своему месту фрагмент
практически неизбежно бывает искажен (зашумлен), что только усложняет задачу.
Например, в длинной строке из 0 и 1 отыскать местонахождение заданного
фрагмента из 0 и 1, который, к тому же, может быть и зашумлен.
Общая схема
Разработанный в ИОНТ РАН алгоритм реализует новый вариант привязки фрагмента в
информационном поле. Для реализации поиска в программе неупорядоченный массив
информации представляется в виде иерархической структуры - дерева поиска, на
котором производится поиск экстремумов. Поиск производится с помощью стека,
который представляет собой также древовидную структуру, которая реализует
известный алгоритм сортировки Heap-Insert-Delete. (Т.Кормен и др. Алгоритмы:
построение и анализ. М.МЦМНО.,2000), для которого число операций вставок и
извлечений пропорционально логарифму от числа элементов стека. Обобщенная
структурная схема решения задачи поиска в целом, представлена на рис. 1.
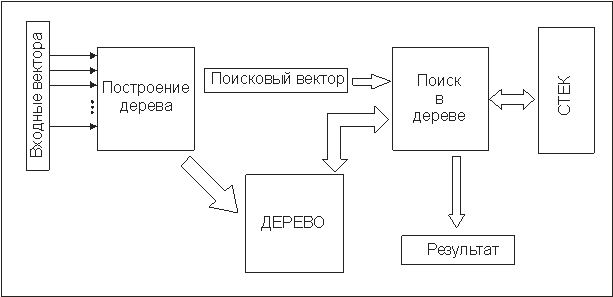
Рис. 1.
Для начала, необходимо записать в памяти ЭВМ эталонное информационное поле, на
котором будет производится поиск. В нашем случае, речь идет о построении
бинарного дерева по заданным входным векторам. За эту процедуру отвечает блок
построения дерева. Бинарное дерево является частным случаем от дерева и имеет
следующие дополнительные свойства:
-
каждый узел может иметь не больше двух порожденных узлов.
-
каждый узел может быть в одном из трех состояний - "пустой", "развилка",
"терминальный".
-
исходный узел имеющий два порожденных узла будем называется "развилкой"
-
порожденный узел являющийся последним называется "терминальным" и
содержит в себе идентификатор.
-
узел не являющийся ни "терминальным", ни "развилкой" называется "пустым".
После того как дерево сформировано, и содержит все эталонные вектора, можно
приступать к поиску. Для этого служит блок поиска в дереве, на вход которого
подается поисковый вектор, возможно зашумленный, а на выходе снимается
результат поиска - идентификатор. В процессе своей работы данный блок,
совершает перемещения по дереву и формирует стек, в котором запоминаются и
выделяются наилучшие из промежуточных результатов поиска. Более детально блоки
построения и поиска в дереве приведены ниже.
Блок построения дерева
Для построения дерева, задается вектор - бинарный массив, размер которого
определяет глубину дерева. Если дерево еще не существует, то строится корневой
узел. Далее производится последовательный просмотр компонент вектора. В случае
если текущий элемент вектора равен "1" строится правый узел дерева относительно
предыдущего, в противном случае левый. При достижении конца вектора, в конечном
узле дерева устанавливается идентификатор записанного в него вектора. Пример
построения дерева приведен на рис.2а. В случае, когда дерево уже существует,
проводится движение по существующему дереву до тех пор, пока его геометрия
соответствует добавляемому вектору. Движение осуществляется аналогично
построению; если текущий элемент вектора равен "1" то производится переход к
правому дочернему узлу, иначе к левому. При выявлении различий между элементом
вектора и дальнейшей геометрией дерева, строится ответвление из текущего узла
(развилка) и производится достройка дерева (рис.2б).
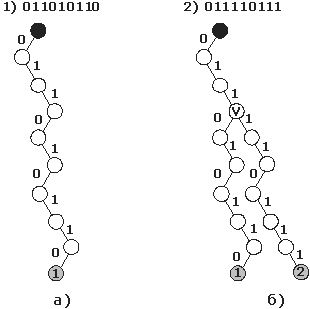
Рис.2
Схема построения дерева.
Такое построение происходит до тех пор, пока не будут запомнены все вектора из
входного набора. Блок поиска в дереве При поиске по предъявленному вектору,
осуществляется ряд рекуррентных операций; формирование стека, вычисление меры
близости (М), сортировка стека при добавлении в него нового элемента, и
сортировка стека при извлечении из него элемента.
Мера близости является величиной характеризующей степень сходства между
вектором представленным для поиска и информацией записанной в ветвях дерева.
На первом этапе в стек помещается корневой узел дерева с мерой близости равной
нулю, далее происходит движение по дереву, при котором на каждом шаге
производится рекуррентное вычисление значения М. Эти значения и адреса
соответствующих узлов заносятся в стек. Далее производится сортировка стека с
целью упорядочивания находящихся в нем элементов по возрастанию. Затем из уже
отсортированного стека извлекается первый элемент содержащий адрес узла дерева
с максимальной мерой близости. Начиная с узла дерева заданной этим адресом
производится дальнейший поиск, до тех пор, пока не будет достигнут либо конец
вектора, либо одна из конечных вершин. Вышесказанное можно представить в виде
алгоритма:
1. Принять М1 = 0, M2=0
2. Принять узел У1 и У2 равными корневому узлу дерева
3. Поместить в стек узлы У1, У2, с мерами близости М1 и М2.
4. Если один из узлов терминальный, то идти к п. 13.
5. Произвести чтение корневого узла стека ' У
6. Найти этот узел в дереве поиска 7. Если узел пустой то, идти к п. 9.
8. Если узел - развилка то, идти к п. 11.
9. Вычислить М1 для порожденного узла У1 от У.
10. Перейти к п.12.
11. Вычислить М1 и М2 для порожденных узлов У1 и У2 от У.
12. Перейти к п. 3.
13. Вывод результата.
14. Конец
Блок стека
Как видно из предыдущего описания, на каждом шаге своей работы блок поиска в
дереве обращается к стеку и производит с ним операции чтения и записи. В стеке,
при каждом обращении к нему, происходит сортировка его содержимого. Конечной
целью это сортировки является помещение в корневой узел стека узла имеющего
максимальное значение меры близости.
Добавление нового элемента в стек производится следующим образом:
1. Если число узлов в дереве стека равно 0, то создается корневая вершина и в
нее записывается содержимое добавляемого элемента.
2. В противном случае вычисляется номер узла, количество потомков
3. Вызывается процедура сортировки стека.
Сортировка производится классическим алгоритмом
Heap-Insert-Delete:
1. В дереве стека выбираются два узла: последний добавленный и его исходный.
2. Сравниваются меры близости записанные в этих узлах. В случае, если мера
порожденного узла больше меры исходного, узлы меняются местами.
3. Далее процесс происходит циклически, поднимая последний добавленный узел
вверх по ветви дерева до тех пор пока, он не займет свое место.
В результате работы этих алгоритмов, в корневой вершине стека будет
находиться узел, содержащий в себе адрес узла дерева-поиска с максимальной
мерой близостью.
После его извлечения, требуется вновь упорядочить стек, возместив отсутствие
корневой вершины.
1. На место корневого узла помещается последний узел дерева стека.
2. Производится сравнение мер близости, содержащихся в трех узлах: текущем и
двух порожденных от него. Для начала выбирается максимальное значение меры
близости среди двух порожденных узлов, а затем это значение сравнивается с
мерой близости в текущем узле.
3. Меняются местами текущий узел и порожденный от него с максимальной мерой
близости.
4. Текущий узел перемещается вниз по дереву до тех пор, пока не займет свое
место в дереве стека.
В результате работы этих трех алгоритмов происходит сортировка стека, которая
позволяет выбирать узел с максимальным значением меры близости, находящемся в
ней.
Для демонстрации алгоритмов построения и поиска, описанных выше, были написаны
демонстрационные программы, описание которых приводится ниже.
Эксперимент
Проводилась несколько серий экспериментов над множеством бинарных деревьев
различной длины. Для поиска задавались последовательности различной длины и
различной степени зашумленности. Каждая серия включала в себя 1000
экспериментов. Сначала была снята характеристика зависимости процента ошибки
(величина обратная мере близости) от процента зашумленности для различных длин
деревьев и для различных длин последовательностей предъявляемых для поиска.
Затем были получены зависимости процента ошибки от процента зашумленности, при
постоянной глубине дерева и длины поисковой последовательности, и переменном
числе векторов записанных в дерево.
Далее проводилась серия экспериментов для снятия зависимости процента ошибки от
числа векторов записанных в дерево постоянной длины, при различной степени
зашумления поисковой последовательности постоянной длины.
И наконец, зависимость числа операций от числа векторов записанных в дереве
постоянной длины, при различной степени зашумления поисковой последовательности
постоянной длины. На основании снятых данных были построены графики,
приведенные на рис. 3.
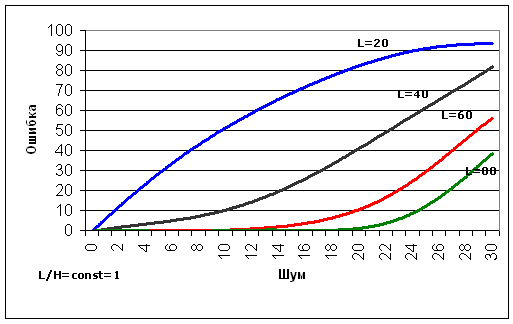
Рис. 3. Зависимость ошибки от шума. L - глубина дерева. H - длина
поискового вектора.
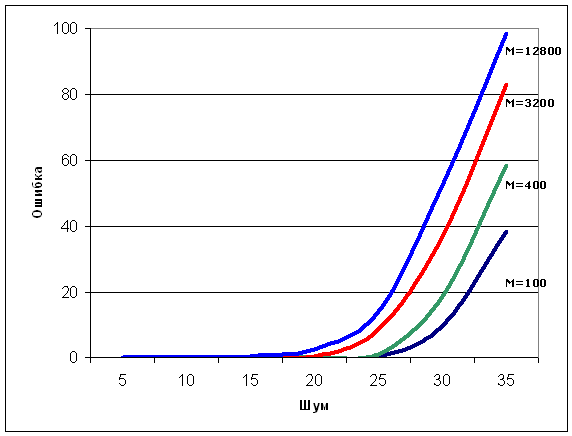
Рис. 4. Зависимость ошибки от шума. Глубина дерева и длина
поискового вектора постоянны и равны. М - число векторов записанных в дерево.
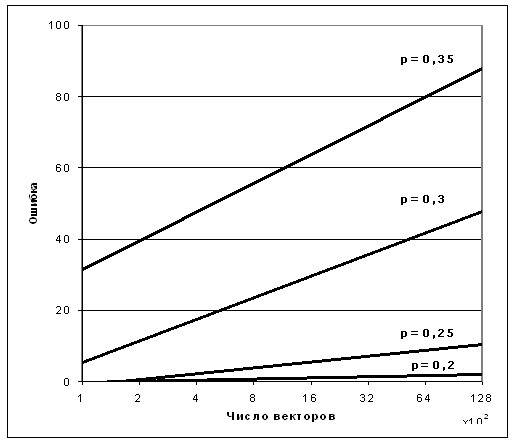
Рис. 5. Зависимость ошибки от количества векторов записанных в
дерево постоянной глубины при различном уровне шума.
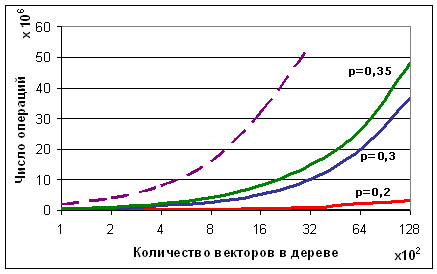
Рис. 6. Зависимость числа операций при поиске от количества
записанных в дерево векторов для различных уровней шума. Глубина дерева и длина
вектора постоянны. Пунктирной линией на графике показана зависимость при
простом переборе без использования бинарного дерева.
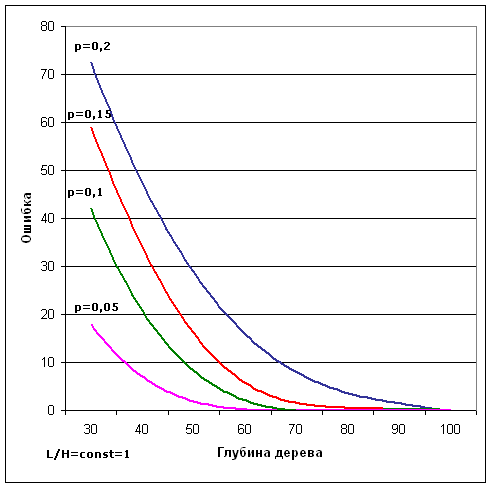
Рис. 7. Зависимость ошибки от глубины дерева при различных
уровнях шума.
Из полученных кривых можно сделать вывод о том, что данный метод показывает
довольно неплохие результаты по всем характеристикам при небольшом количестве
векторов записанных в дерево(~100-200). При увеличении этого числа или
зашумленности входной последовательности, резко возрастает процент ошибки и
количество операций необходимое для произведения поиска. Это связано с тем, что
при прохождении дерева в процессе поиска, в этих условиях, число проходимых
узлов резко увеличивается и приближается к половине всех узлов, на которых
построено дерево, следовательно, на каждом такте затрачивается значительное
машинное время для его сортировки.
Из экспериментов была найдена ошибка распознавания Ver, значение которой можно
выразить формулой
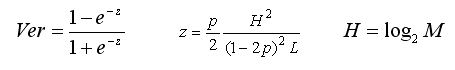
Наибольший интерес для практического использования представляет та область
переменных (область допустимости), в которой ошибка распознавания Ver
<<1, что достигается при z <<1. При этом Ver ≈ z.
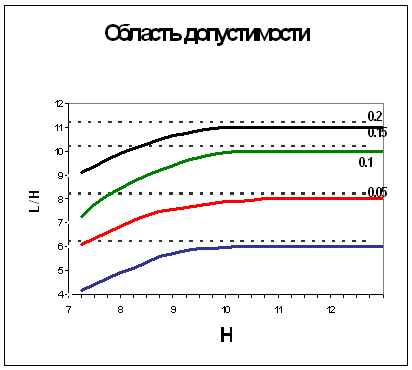
Рис.8 Область допустимых значений L/H при различных уровнях шума.
На рис.8 приведены кривые, построенные для различных уровней искажений (p=0,05;
0,10; 0,15; 0,20). Сплошная линия разграничивает области применения алгоитма
поиска: для точек, расположенных ниже кривой (малые значения L/H ) число
операций недопустимо велико, т.е. нарастает экспоненциально с ростом числа
векторов М, а ошибка распознавания больше 0,01; в области выше кривой алгоритм
успешно работает и его быстродействие приближается к теоретическому пределу, а
ошибка распознавания меньше 0,01. Для разграничения областей допустимости и
недопустимости вместо кривых удобнее использовать их асимптоты - пунктирные
линии на рис.8.
Например, при p<0,05 областью допустимости являются значения L/H>6, то
есть для успешной работы алгоритма поиска следует использовать дерево с
глубиной L>6log2M.
Под областью допустимости мы подразумеваем область значений параметров, при
которых вероятность ошибки Vош пренебрежимо мала, а число операций растет
линейно с ростом глубины дерева L, то есть:
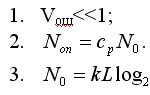
где N0 - число операций в отсутствии шумов, а экспериментально установленная
величина Cp мало отличается от единицы:
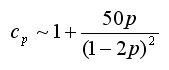
Величина k в этом выражении линейно зависит от L, порядка k~C1+C2(L+H)lnH~100,
где C1 и C2 - несущественные константы (см. ниже). Первое слагаемое отображает
движение по дереву поиска. Второе слагаемое в этом выражении связано с
операциями чтения и записи в стек. Обобщая анализ области допустимости, следует
рекомендовать следующие параметры, при которых алгоритм поиска работает
успешно: относительно малый уровень шумов p?0,2 и достаточно большая глубина
дерева L>10 log2M .
Описание демонстрационной программы поиска зашумленной
бинарной последовательности в дереве.
После запуска программы на выполнение (demo2.exe) будет произведена загрузка
бинарного текста в дерево (рис.9)
Рис. 9.
Затем, перед пользователем появится форма изображенная на рис.10, на которой
расположено поле загруженного в дерево текста, и имеется строка для ввода
поисковой строки - "Строка поиска".
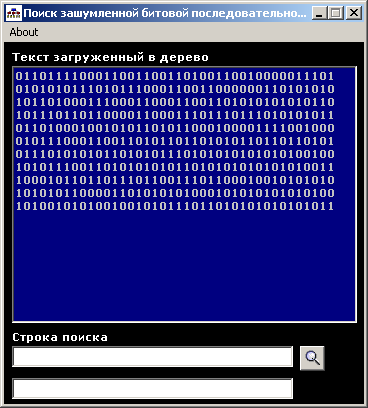
Рис. 10.
После ввода в нее бинарной последовательности, последовательности, необходимо
нажать кнопку поиска ( ). Результат
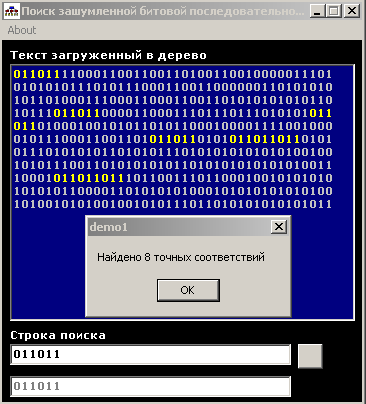
выдаваемый программой может быть различным в зависимости от того встречается ли
введенная последовательность в сформированном дереве целиком, или нет. В первом
случае будет выдано соответствующее сообщение и выделены все соответствующие
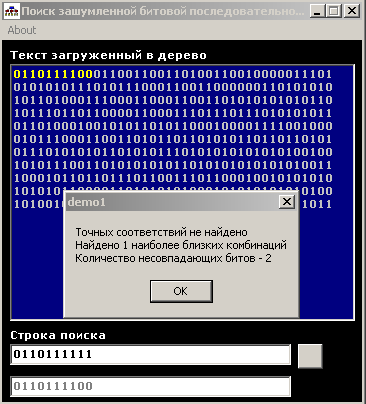
области в тексте (рис. 11). Во втором будет выведено сообщение о том что точных
соответствий не найдено, и произведен поиск наиболее близких вхождений по
дереву (рис. 12). ). Результат
выдаваемый программой может быть различным в зависимости от того встречается ли
введенная последовательность в сформированном дереве целиком, или нет. В первом
случае будет выдано соответствующее сообщение и выделены все соответствующие
области в тексте (рис. 11). Во втором будет выведено сообщение о том что точных
соответствий не найдено, и произведен поиск наиболее близких вхождений по
дереву (рис. 12).
|
|
|
|
Рис. 11
|
Рис. 12
|
В целях недопущения некорректного ввода, проверяется входная последовательность
на наличие посторонних символов. После произведения поиска, до подачи новой
поисковой строки, кнопка поиска отключена.
 Скачать демонстрационную программу
(274 кБ)
Скачать демонстрационную программу
(274 кБ)
Демонстрационная программа привязки на местности.
Для демонстрации алгоритма быстрого поиска по заданной последовательности в
бинарном дереве, была написана программа имитирующая полет объекта в
пространстве. При запуске файла UFO.exe после некоторой задержки, во время
которой происходит формирование карты местности, перед пользователем появляется
окно изображенное на рис. 13.
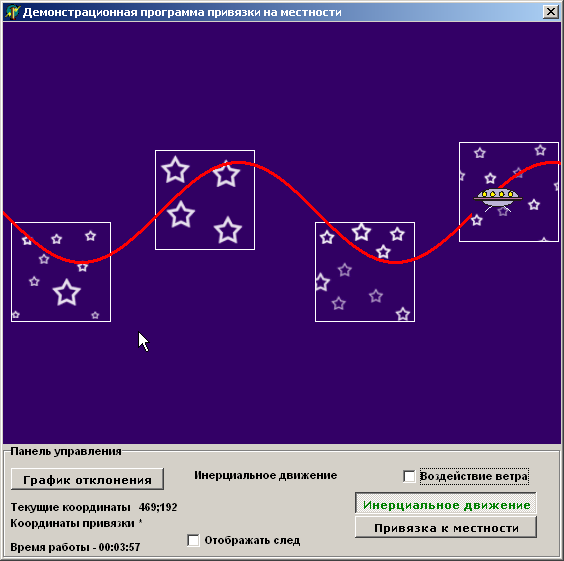
Рис. 13.
Красная кривая на рисунке, представляет собой траекторию, которой должен
придерживаться объект. Выделенные области звездного неба представляют собой
участки в которых объект может определять свои координаты, производя поиск по
бинарному дереву. Вне этих областей объект движется инерциально, повторяя
заложенную в памяти траекторию движения. В этом случае при воздействии
возмущающих сил - "Ветра" происходит его отклонение от заданного курса (рис.
14).

Рис. 14.
В нижней части окна программы расположен ряд кнопок и переключателей
переключащих режимы ее работы. В частности, можно включать и отключать
воздействие "ветра" с помощью соответствующего переключателя, отображать
реальную траекторию движения объекта, наблюдать график отклонения от заданного
курса (рис. 15).
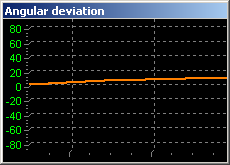
Рис. 15.
Кроме того, имеется возможность переключиться из работающего по умолчанию режима
инерциального движения объекта в режим привязки к местности и обратно, с
помощью соответствующих кнопок. В режиме привязки к местности, программа
формирует бинарный вектор местности, в которую попал объект и производит поиск
этого вектора в дереве. В результате определяются координаты объекта
относительно текущей области привязки и производится корректировка курса (рис.
16а, 16б);

Рис. 16а. Режим привязки к местности включен с самого начала
движения
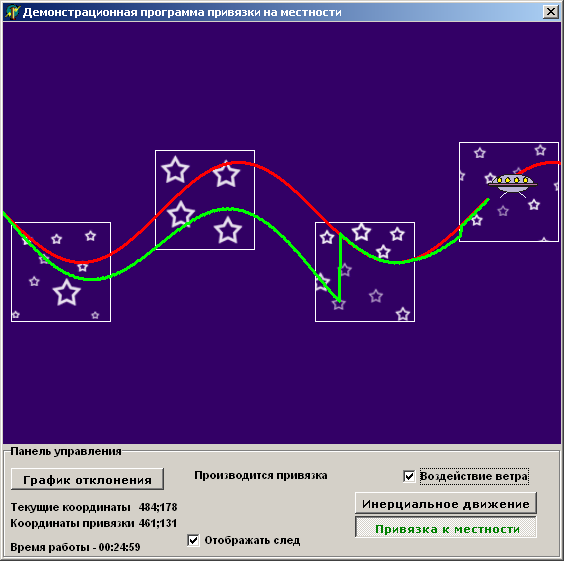
Рис. 16б.Режим привязки включен после уже значительного
отклонения объекта.
Скачать демонстрационную программу
(363 кБ)
Литература
-
Кнут Д., Искусство программирования для ЭВМ. Сортировка и поиск, т.3, М., Мир,
1978.
-
Кормен Т. и др., Алгоритмы: построение и анализ, М., МЦМНО, 2000
|